Help
Searching the Web Archive
What can be found in the New Zealand Web Archive
The Web Archive Discovery Platform provides public access to the New Zealand Web Archive. The full-text of web pages and documents (PDF, text, Word, Excel, PowerPoint and others) have been indexed and are searchable.
This does not include any boilerplate HTML code that is used by a web browser to render a web page. However, it can include text from rendered headers, footers, menus and navigation elements.
The Web Archive Discovery Platform does not currently index media such as, images, audio and video. Such items can still be discovered by searching on the context of the surrounding web pages that link to or embed them.

Different types of Search options
Searching all Text
Use this option to search for any text relating to a web page or document, including text content, title, URL and Domain.
Search Tips:
- All text searches are case insensitive.
- By default, any words in a search are treated as individual words. For example, searching for the words Queens Birthday Weekend, may return results that:
- contain all three words in sequence.
- contain all three words, out of order, or separately and in different locations.
- contain one or more of the words.
- Search results will be ranked by the proximity of those words together, and their frequency.
- By default, the following list of stop words are ignored during searching: a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with.
- If searching for a phrase, surround your text in double quotes, e.g. "Home of the Paekakariki Express".
Searching by Title
Use this option to search for any title of a web page. Titles are the text content extracted from the HTML title tag of a page, i.e. "<title>". This is the text that is displayed in a web browser’s title bar, or web page’s tab.
While the title tag is required in HTML documents, its text does not always match what appears to be a title rendered within a web page, as this is at the web page author’s discretion.
Search Tips:
- All title searches are case insensitive.
- By default, any words in a search are treated as individual words. For example, searching for the words Queens Birthday Weekend, may return results that:
- contain all three words, in sequence, or out of order, within a title.
- contain one or more of the words within a title.
- Search results will be ranked by the proximity of those keywords together, and their frequency.
- By default, the following list of stop words are ignored during searching: a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with.
- If looking for an exact match, surround your text in double quotes, e.g. "A Romance of Lake Wakatipu".
Searching by URL
Use this option to search for any URL of a web page or document.
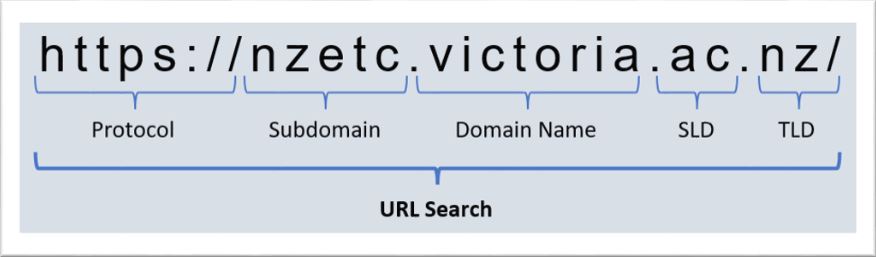
Search Tips:
- URL searches are case insensitive.
- URL searches expect and are sensitive to the protocol of the URL, i.e. http or https. For example, if you include the protocol (http, https) as part of the URL search it will only match the results that have that same protocol.
- URL searches perform an exact match. To perform partial searches of a URL, prepend or append your text with wildcards *, for example:
- *nzetc.victoria.ac.nz/tm/scholarly/tei-corpus-nhsj.html (find any URL that ends with this text)
- https://nzetc.victoria.ac.nz/tm/scholarly/tei-corpus-nhsj* (find any URL that starts with this text)
- *tei-NHSJ06_03* (find any URL that contains this text)
Searching by Domain
Use this option to search for any domain of a web page or document. The term domain is broadly used to cover domain, subdomain and hostname in the context of this search.
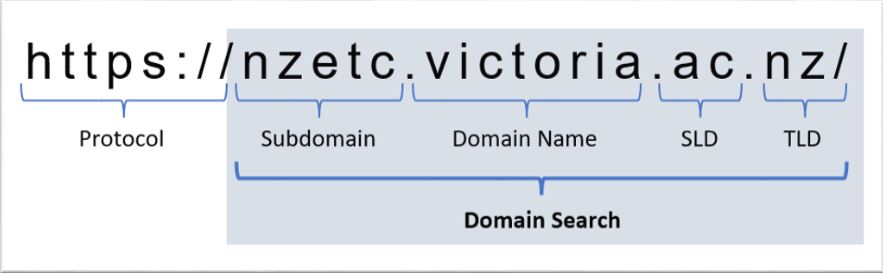
Search Tips:
- Domain searches are case insensitive.
- Do not include any protocol in your domain search, i.e. http:// or https://.
- Domain searches perform an exact match. To perform partial searches of a domain, prepend or append your text with wildcards *, for example:
- *victoria.ac.nz
- nzetc*
- *dia.govt.nz
- *govt.nz*
- *school*
Search Facets
On the search result page, you will find the search facets on the left side of the page. Search facets allow you to narrow the results. There are six available facet types. Within each facet, you will see a summary of values that can be clicked on to narrow your search.
When a facet has been applied, it will appear as a box above the search results. To remove an applied facet, simply click the 'x' button on it.

See below for a description of the available facets.
Collection
The Collection facet refers to a collection of harvested web pages or documents, for example the archived web pages that make up the New Zealand Electronic Text Collection (NZETC). Collections are added incrementally to this discovery platform.
Content Type
The Content Type facet refers to the general content type that has been determined when indexing a web page or document. Apache Tika is used to identify content types and formats in the indexing process.
The first part of a format identification is used to determine the general content type. See the formats below and their corresponding content type:
- "text/html; charset=UTF-8" : "html"
- "application/pdf; version=1.4" : "pdf"
- "text/plain; charset=UTF-8" : "text"
- "application/vnd.ms-powerpoint" : "powerpoint"
Be aware that occasionally web pages or documents can be classified with the wrong content type. And if a content type can't be determined, then a classification of "Other" will be assigned. If you can’t find a document based on its content type, try performing a URL search for its file extension, e.g. *.doc.
Crawl Year
The Crawl Year facet refers to the year in which the web page or document was harvested by the National Library. This is not the same as a year of publication, although it’s possible they could be the same.
Public Suffix
The Public Suffix facet refers to the combination of the top-level domain (TLD) and possible second-level domain (SLD), of a URL for a web page or document. For example, in .govt.nz, "nz" is the TLD, and "govt" is the SLD. There are many URLs that also contain just a TLD, such as .com or .nz.

See the examples below of common public suffixes:
- .govt.nz
- .ac.nz
- .parliament.nz
- .org.nz
- .co.nz
- .com
- .net
Domain
The Domain facet refers to the registered domain name for a web page or document. A domain name consists of a hierarchical sequence of names separated by periods (dots) and ending with a top-level domain.
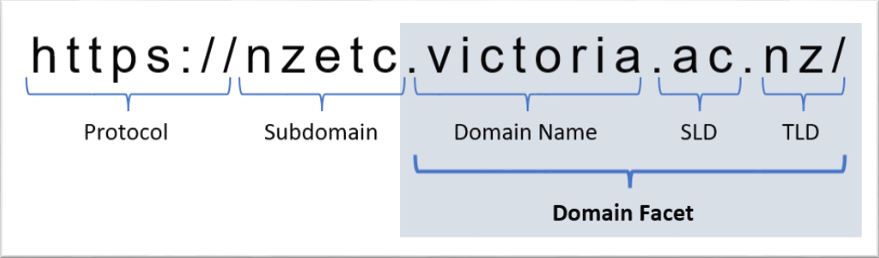
See the examples below of common domain names:
- natlib.govt.nz
- elections.org.nz
- scoop.co.nz
- wordpress.com
Be aware that this facet does not include subdomains beyond the public suffix and initial domain. See the examples below of subdomains that would not show under the facet:
- nzetc.victoria.ac.nz
- news.google.co.nz
- play.stuff.co.nz
To search specifically for subdomains, use the URL search with wildcards *, e.g. *nzetc.victoria.ac.nz*
Search Results

Search results contain the following metadata fields: view, type, date collected, collections and sample. These are described below.
View
A link to view the web page or document within the National Digital Heritage Archive.
Type
The content type and language detected for the web page or document.
Date Collected
The date and time that the web page or document was harvested by the National Library.
Collections
Any collections that the web page or document belong to within the New Zealand Web Archive.
Sample
A selection of text highlighting the first match of any search terms within the web page or document content.